論文筆記 — Momentum Contrast for Unsupervised Visual Representation Learning(MOCO)
論文網址:https://arxiv.org/abs/1911.05722
之前介紹過🍄SimCLR可以幫助模型在classification之類的下游任務上獲得更好的效果,今天來看一些更早期的論文。
Abstract
我們提出了用於無監督視覺表示學習的 Momentum Contrast (MoCo)。 從contrast learning 作為字典查找的角度來看,我們構建了一個帶有queue和moving average Encoder 的 Dynamic Dictionary。 這使得能夠即時構建一個大型且一致的字典,以促進contrast 無監督學習。 MoCo 在 ImageNet 分類下獲得不錯且有競爭力的結果。 更重要的是,MoCo 學習的表示可以很好地轉移到下游任務。 在 PASCAL VOC、COCO 和其他數據集上的 7 個檢測/分割任務中,MoCo 可以勝過其他supervised 的預訓練對手,甚至顯著超過他們。
1. Introduction
最近的幾項研究提出了使用 contrast loss的方法進行無監督視覺表示學習的結果。 儘管受到各種動機的驅動,這些方法可以被認為是構建Dynamic Dictionary。 字典中的“key”是從數據(例如圖像或patch)中採樣的,並由Enocoder Network表示。 無監督學習訓練Encoder 去進行字典“look-up”:編碼的“query”應該與其matching-key 相似,而與其他key不同。
從這個角度來看,我們假設構建的是:(i)Large和(ii)consistent 且在訓練過程中不斷發展的字典。 直觀地說,更大的字典可能更好地對底層連續的高維視覺空間進行採樣,而字典中的key應該由相同或相似的Encoder表示,以便它們與查詢的比較是一致的。 然而,使用contrast loss的現有方法可能在這兩個方面之一受到限制。
我們提出 Momentum Contrast (MoCo) 作為一種為具有對比損失的無監督學習構建大型且一致的字典的方法(如下圖)。 我們將字典維護為一個型態為data sample 的 queue:當前小批量的Encoded 的representation 做Enqueue,最舊的表示Dequeue。

由於diction keys來自前面的幾個小批量,因此作者設立了一個緩慢發展的key-Encoder,實現為查詢編碼器的momentum-based的移動平均值,以保持一致性。
2. Related
有興趣可以再去原文那邊看
3. Method
3.1. Contrastive Learning as Dictionary Look-up
考慮一個Enocer query q 和一組Encoder sample{k0, k1, k2, …},它們是字典的keys。 假設在 q 匹配的字典中有一個key(表示為 k+)。 Contrast Loss是一個函數,當 q 與其正鍵 k+ 相似但與所有其他鍵(被視為 q 的negative keys)不同時,該函數的值較低。 通過dot product測量相似度,本文考慮了一種稱為 InfoNCE 的對比損失函數:

總和考慮了 1 個正樣本和 K 個負樣本。 直觀地說,這種損失是K+1 個sample 於 softmax 的分類器的log loss,該分類器試圖將 q 分類為 k+。 對比損失函數也可以基於其他形式 ,例如margin-based losses和 NCE losses的變體。
一般變數說明:查詢表示是 q = fq(xq),其中 fq 是編碼器網絡,xq 是查詢樣本(同樣,k = fk(xk))。
3.2. Momentum Contrast
從上述角度來看,對比學習是一種在圖像等高維連續輸入上構建字典的方法。 字典是動態的,因為keys是隨機採樣的,keys Encoder在訓練期間會演變。 我們的假設是,好的特徵可以通過一個包含大量負樣本的大型字典來學習,而字典鍵的編碼器儘管在進化,但仍盡可能保持一致。 基於此動機,我們提出如下的Momentem Contrast。
Dictionary as a queue.
字典中的樣本被逐步替換。 當前的 mini-batch 被排入字典,Queue中最舊的 mini-batch 被刪除。 字典總是代表所有數據的一個sampled subset,而維護這個字典的額外計算是可控的。 此外,刪除最舊的 mini-batch 可能是有益的,因為它的Encoder leys是最過時的,因此與最新的最不一致。
Momentum update.
使用隊列可以使字典變大,但它也使得通過反向傳播更新key-Encoder變得更難。 一個簡單的解決方案是從Query-Encoder fq 複製Key-Encoder fk,忽略這個梯度。 但是這個解決方案在實驗中產生了很差的結果,我們假設這種失敗是由快速變化的編碼器引起的,這降低了我們希望的representation 一致性。 我們提出Momentum update 來解決這個問題。
形式上,將 fk 的參數表示為 θk,將 fq 的參數表示為 θq,我們通過以下方式更新 θk:
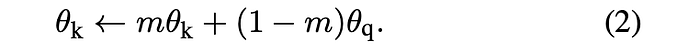
只有參數 θq 通過反向傳播更新。 上面等式(2) 中的Momentum Update 使得 θk 的收斂比 θq 更平滑。 結果,儘管Queue中的Key由不同的編碼器(在不同的小批量中)編碼,但這些編碼器之間的差異可以很小。 在實驗中,相對較大的動量(例如,m = 0.999,我們的默認值)比較小的值(例如,m = 0.9)效果更好。
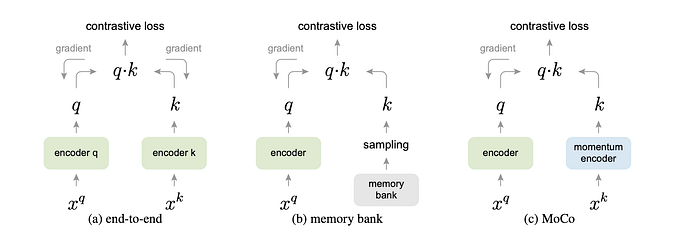
Relations to previous mechanisms.
3.3. Pretext Task
對比學習可以驅動各種下游任務,所以在這裡我們使用一個簡單的實例識別任務進行實驗。如果查詢和鍵來自同一圖像,我們將它們視為正對(positive-pair),否則視為負樣本對。 我們在隨機數據增強下對同一圖像進行兩個隨機“視圖”以形成正對。 查詢和鍵分別由它們的編碼器 fq 和 fk 編碼。 編碼器可以是任何卷積神經網絡。下圖的算法為MoCo的pseudo-code

4. Experiments
對實驗細節感興趣可以去原文查看更多,這裡就不細講。
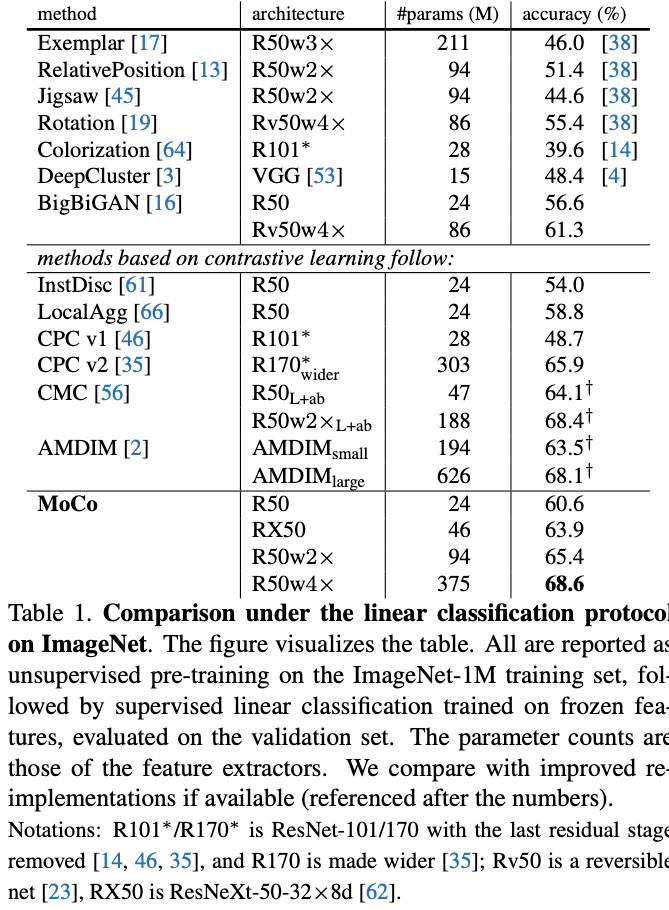
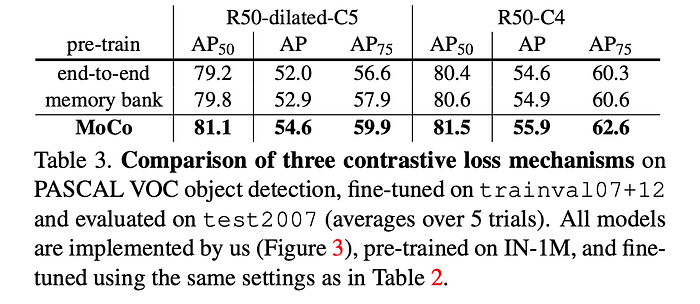
5. discussion
我們的方法在各種計算機視覺任務和數據集中顯示出無監督學習的積極成果。 一些開放性問題值得討論。 MoCo 從 IN-1M (ImageNet-1M)到 Instagram-1B (IG-1B) 的改進一直很明顯,但相對較小,這證明MOCO可能無法充分利用更大規模的數據。 我們希望高級的下游任務能夠改善這一點。 除了簡單的classification 任務之外,還可以將 MoCo 用於Mask auto-encoding或是其他涉及對比學習的任務。