Paper Notes — Vision Transformer Adapter for Dense Predictions
paper link: https://arxiv.org/abs/2205.08534
Introduction
Problem
ViT can use large-scale multi-modal data for pre-training, which makes the features captured by the model have richer semantics. But ViT has conclusive defects in downstream tasks compared to task-specific transformers.
Inspired by the adapter in the NLP field, this work aims to develop an adapter to close the gap between vanilla transformers such as ViT and the dedicated models for downstream vision tasks.

In this framework, the backbone network is a general model (e.g., ViT) that can be pre-trained with multi-modal data and tasks.
When applying it to downstream tasks, this vision-specific adapter is used to introduce the prior information of input data and tasks to the general backbone, making the model suitable for downstream tasks.
In this way, it can achieve better performance than transformer backbones such as Swin Transformer, specifically designed for dense prediction tasks.
Related Work
Transformer
- PVT and Swin Transformer achievie superior performance in classification and dense prediction tasks while sacrificing the generalization ability of other modalities to some extent by incorporating the pyramid structure from CNNs.
- Conformer proposed the first dual network to combine CNN with transformer.
- BEiT and MAE extended the scope of ViT to self-supervised learning with masked image modeling, demonstrating the powerful potential of the pure ViT architecture.

Decoders for ViT
- SETR is the first work to adopt ViT as the backbone and develop several CNN decoders for semantic segmentation
- Segmenter also extends ViT to semantic segmentation, but differs in that it equips a transformer-based decoder.
- DPT further applies ViT to the monocular depth estimation task via a CNN decoder and yields remarkable improvements.

Adapters
- Adapters have been widely used in the NLP field.
- With the advent of CLIP, many CLIP-based adapters were presented to transfer pre-trained knowledge to zero-shot or few-shot downstream tasks.
Architecture
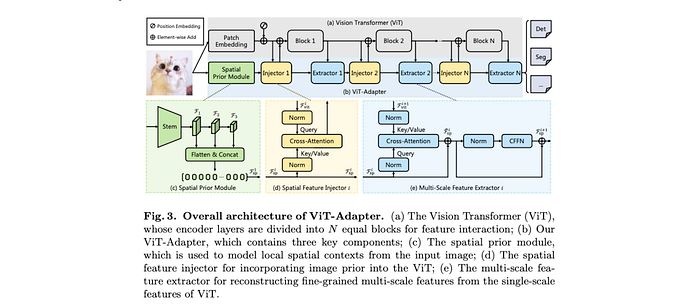
Spatial Prior Module
Recent works show convolutions with overlapping sliding windows can help transformers better capture the local continuity of input images.
Inspired by this, we introduce a convolution-based Spatial Prior Module into ViT, which downsamples a H×W input image to different scales(⅛, 1/16, 1/32 ) via a stem followed by three convolutions.
Spatial Feature Injector
This module is used to inject the spatial priors into ViT, take the feature from ViT as query and the spatial feature as key/value. Using multi-head cross-attention to inject spatial feature.
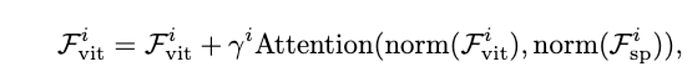
To reduce the computational cost, we adopt deformable attention, a sparse attention with linear complexity, to implement the attention layer.
In addition, we apply a learnable vector γi ∈ RD to balance the attention layer’s output and the input feature Fi , which is initialized with 0.
Multi-scale Feature Extractor
After injecting the spatial priors into the ViT, we obtain the output feature Fi+1 by passing Fi through the encoder layers of the i-th block. After that, we swap the roles of ViT’s feature and the spatial feature.
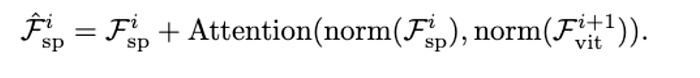
We introduce the convolutional feed-forward network (CFFN) after the cross-attention layer. The CFFN layer enhances the local continuity of features via depthwise convolution with zero-padding.

Experiments
Object Detection and Instance Segmentation Setting
- Object detection and instance segmentation are conducted on the COCO benchmark, and our codes are mainly based on MMDetection.
- In the training phase, we use the DeiT released weights for ViT-T/S/B.
- The newly added modules of our adapter are randomly initialized and no pre-trained weights are loaded.
- To save time and memory, we modify the ViT to use 14×14 window attention in most layers.
- Following common practices like Mask R-CNN, we adopt 1× or 3× training schedule (i.e. 12 or 36 epochs) to train the detectors, with a batch size of 16 and AdamW optimizer with an initial learning rate of 1 × 10−4 and weight decay 0.05.
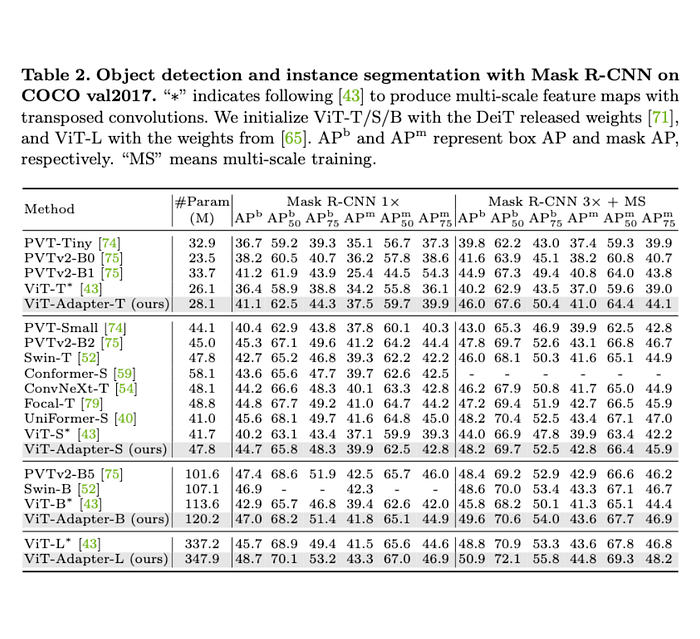
Object Detection and Instance Segmentation Result
With our adapter, ViT can achieve significant improvements on object detection and instance segmentation tasks. For example, with the 3×+MS training schedule, ViT-Adapter-T outperforms PVT-Tiny by 6.2 APb and 3.6 APm, while our parameter number is 15% fewer.
The results of ViT-Adapter-S are 2.2 APb and 1.2 APm higher than Swin-T with similar model sizes. Moreover, our ViT-Adapter-B achieves a promising accuracy of 49.6 APb and 43.6 APm, surpassing previous state-of-the-art methods such as PVTv2-B5 and Swin-B. Our best model ViT-Adapter-L with ImageNet-22K pre-trained weights, yields 50.9 APb and 44.8 APm, bringing 2.1 APb and 1.2 APm gains over the baseline.
Semantic Segmentation Setting
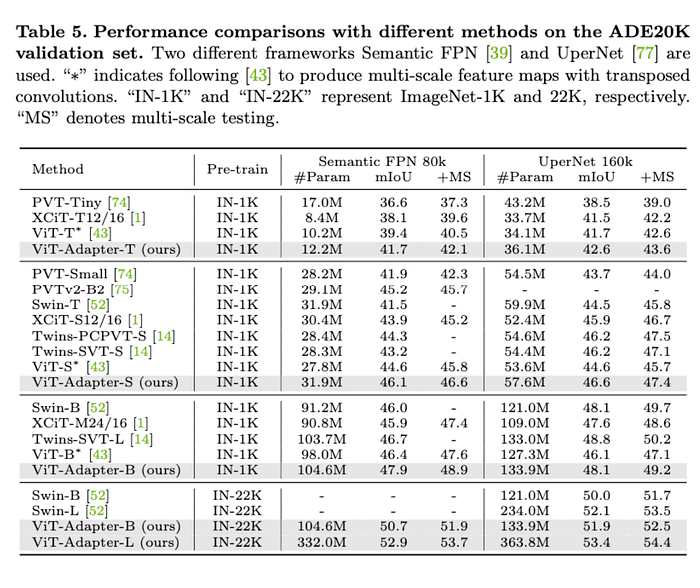
We evaluate our ViT-Adapter on semantic segmentation with the ADE20K and MMSegmentation . For a complete comparison, we employ both the Semantic FPN and UperNet as the basic frameworks.
For Semantic FPN, we apply the settings of PVT and train the models for 80k iterations. For UperNet, we follow the settings of Swin to train it for 160k iterations. In addition, we initialize ViT-T/S/B with the DeiT released weights, and ViT-L with the ImageNet-22K weights.
Semantic Segmentation Result
We report the semantic segmentation results in terms of single-scale and multi-scale mIoU. We first consider the Semantic FPN, which is a simple and lightweight segmentation framework without complicated designs. Under comparable model sizes, our method surpasses previous repre- sentative approaches by clear margins.
Ablation Study
As shown in the bottom table, our spatial prior module and multi-scale feature extractor improve 3.2 APb and 1.6 APm compared to the baseline. From the results of variant 2, we find that spatial feature injector brings 0.8 APb and APm improvements, showing that the local continuity information can promote the performance of ViT on dense prediction tasks, and its extraction process can be decoupled from the architecture of ViT.
Furthermore, we employ CFFN to introduce additional position information, which brings 0.5 APb and 0.4 APm gains, alleviating the drawbacks of fixed-size position embeddings used in ViT.

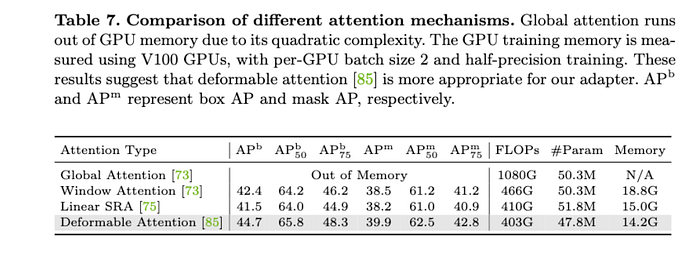
We study 4 different attention mechanisms, including global attention, window attention, linear SRA , and deformable attention.
When adopting global attention in our adapter, it will exhaust the GPU memory (32G) due to quadratic complexity. Window attention and linear SRA can significantly reduce the computational cost, but they are limited to capturing local and global dependencies respectively, leading to the relatively weak modeling capability.
Conclusion
Without changing ViT’s architecture, we inject image prior into the ViT and extract the multi-scale features via a spatial prior module followed by two feature interaction operators.
Extensive experiments on object detection, instance segmentation, and semantic segmentation benchmarks verify that our models can achieve comparable and even better performance than well-designed vision-specific transformers under comparable number of parameters.
